Paper Review—Mesh R-CNN
October 04, 2020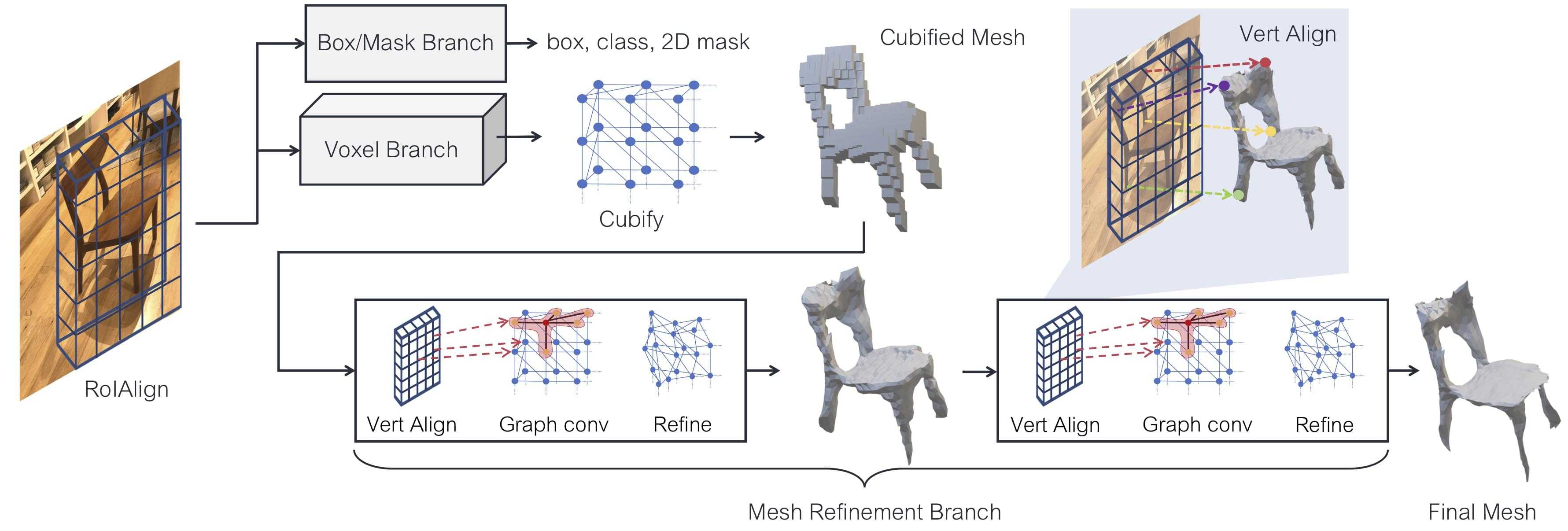
Main Contribution
Drawing inspiration from the state-of-art networks in 2D perception and 3D shape prediction, this paper is tackling the problem of 3D object reconstruction. Given a real-world input image, the network aims to output 2D instance segmentation results and 3D triangle mesh for each detected object. The main contribution of this paper includes the proposal of Mesh R-CNN, which extends Mask R-CNN with a novel mesh predictor branch designed for 3D shapes and achieves state-of-art results.
Additionally, Mesh R-CNN is a pioneer in 3D shape prediction in real-world cluttered scenes with a variety of objects. This research problem is important for real-world applications such as autonomous driving, virtual reality, and other emerging domains.
The main novel part of the method is to find the right way to predict meshes in the neural network, where they use an iterative mesh refinement with hybrid shape representation to overcome the fixed topology in previous mesh deformation works.
Method
Mesh R-CNN expands the 2D instance segmentation system (Mask R-CNN) by adding a mesh prediction branch, which is composed of a hybrid approach of voxel prediction followed by mesh refinement. This two-step approach, according to the authors, helps predicting fine-grained 3D structures. Starting from a RGB input image, the network will first perform 2D instance segmentation, same as Mask R-CNN, to get features per region. Then it will predict a coarse 3D structure as a voxelized prediction for each ROI in the voxel branch, which is later cubified to mesh for the mesh branch, including vertex alignment, graph convolution and refinement stages.
In vertex alignment, the vertices in the current mesh are projected onto the image plane, and then an aligned feature from the image plane is sampled. Graph convolution merges information along neighbouring vertices in the mesh structure. The mesh refinement stage predicts offsets for all the vertices in the mesh to update the positions.
In defining the loss of mesh, they convert the mesh into point clouds by sampling the points from the surface and calculate the chamfer distance against the ground truth with regularization to enforce smoothness. Chamfer distance seems to be the L2 distance in 3D shapes, and it could be sensitive to outliers. One limitation of this paper I identified is not experimenting with other metrics, such as F1 score, and/or justify why they have chosen chamfer distance.
Finally, the voxel and mesh losses alongside the box and mask losses for 2D instance segmentation are used to train the system end-to-end. The results of Mesh R-CNN outperforms its prior work, and it has reasonable completion of the objects even if an object is occluded.
What do I think?
One thing I found interesting is that compared to the high performing 2D network Mask R-CNN, this network is also trained using fully supervised learning with pairs of images and meshes, however with a much smaller dataset. The Pix3D dataset used for training and testing only contains 10,069 pairs of images and meshes, much smaller than a standard 2D training dataset, such as COCO.
Imaginable, a 3D dataset is a lot harder to collect and obtain, since it requires expertise to create and annotate the ground truth. I think this work has chosen an intelligent way to deal with this problem, which is “standing on the shoulder of” high-performing 2D fully supervised network and ripe the benefits from the 2D supervision (using a pre-trained model for instance segmentation on COCO).
Future Work
Relying on 3D supervision doesn’t seem to be the optimal solution, if unsupervised or semi-supervised methods could be developed to relax this constraint. Since there are already 2D examples in unsupervised networks, such as GAN or conditional GAN, this seems like a feasible possible extension.